


深入理解Linux网络——内核与用户进程协作之同步阻塞方案(BIO)
系列文章:
- 深入理解Linux网络——内核是如何接收到网络包的
- 深入理解Linux网络——内核与用户进程协作之同步阻塞方案(BIO)
- 深入理解Linux网络——内核与用户进程协作之多路复用方案(epoll)
- 深入理解Linux网络——内核是如何发送网络包的
- 深入理解Linux网络——本机网络IO
- 深入理解Linux网络——TCP连接建立过程(三次握手源码详解)
- 深入理解Linux网络——TCP连接的开销
在上一部分中讲述了网络包是如何从网卡送到协议栈的(详见深入理解Linux网络——内核是如何接收到网络包的),接下来内核还有一项重要的工作,就是在协议栈接收处理完输入包后要通知到用户进程,如何用户进程接收到并处理这些数据。
进程与内核配合有多种方案,这里我们这分析两种典型的:
-
同步阻塞方案(Java中习惯叫BIO)
-
多路IO复用方案(Java中对应NIO)
- Linux多路复用有select、poll、epoll,这里只讲性能最优秀的epoll
本文主要讲的是同步阻塞模式的实现方案,多路IO复用方案及问题解答见文章深入理解Linux网络——内核与用户进程协作之多路复用方案(epoll)
一、相关实际问题
- 阻塞到底是怎么一回事
- 同步阻塞IO都需要哪些开销
- 多路复用epoll为什么就能提高网络性能
- epoll也是阻塞的吗
- redis为什么网络性能突出
二、socket的直接创建
以开发者的角度来看,调用socket函数可以创建一个socket
int main()
{
int sk = socket(AF_INET, SOCK_STREAM, 0);
......
}
等这个socket函数调用执行完以后,用户层面看到返回的是一个整数型的句柄,但其实内核在内部创建了一系列的socket相关的内核对象(不止一个)。它们之间相互的关系如下:
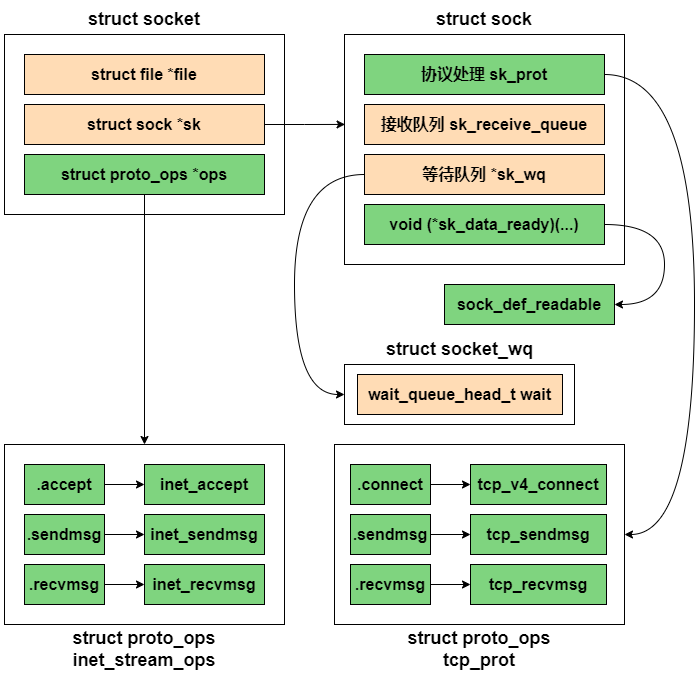
socket在内核中的定义如下:
struct socket {
socket_state state;
unsigned long flags;
const struct proto_ops *ops;
struct fasync_struct *fasync_list;
struct file *file;
struct sock *sk;
wait_queue_head_t wait;
short type;
};
typedef enum {
SS_FREE = 0, //该socket还未分配
SS_UNCONNECTED, //未连向任何socket
SS_CONNECTING, //正在连接过程中
SS_CONNECTED, //已连向一个socket
SS_DISCONNECTING //正在断开连接的过程中
}socket_state;
socket是内核抽象出的一个通用结构体,主要是设置了一些跟fs相关的字段,而真正跟网络通信相关的字段结构体是struct sock。
struct sock是网络层对于struct socket的表示,其中成员非常多,这里只介绍其中一部分。
sk_prot和sk_prot_creator,这两个成员指向特定的协议处理函数集,其类型是结构体struct proto,该结构体也是跟struct proto_ops相似的一组协议操作函数集。这两者之间的概念似乎有些混淆,可以这么理解,struct proto_ops的成员操作struct socket层次上的数据,处理完了,再由它们调用成员sk->sk_prot的函数,操作struct sock层次上的数据。即它们之间存在着层次上的差异。struct proto类型的变量在协议栈中总共也有三个,分别是mytcp_prot,myudp_prot,myraw_prot,对应TCP, UDP和RAW协议。
sk_state表示socket当前的连接状态,是一个比struct socket的state更为精细的状态,其可能的取值如下:
enum { TCP_ESTABLISHED = 1, TCP_SYN_SENT, TCP_SYN_RECV, TCP_FIN_WAIT1, TCP_FIN_WAIT2, TCP_TIME_WAIT, TCP_CLOSE, TCP_CLOSE_WAIT, TCP_LAST_ACK, TCP_LISTEN, TCP_CLOSING, TCP_MAX_STATES; }- 这些取值从名字上看,似乎只使用于TCP协议,但事实上,UDP和RAW也借用了其中一些值,在一个socket创建之初,其取值都是TCP_CLOSE,一个UDP socket connect完成后,将这个值改为TCP_ESTABLISHED,最后,关闭sockt前置回TCP_CLOSE,RAW也一样。
sk_rcvbuf和sk_sndbuf:表示接收和发送缓冲区的大小。这两个值是动态的,应用程序可以通过setsockopt系统调用来改变它们的值。但是,这些值也受到了一些全局内核参数的限制(通常由/proc/sys/net/core/rmem_default(对于接收缓冲区)和/proc/sys/net/core/wmem_default(对于发送缓冲区)这两个内核参数来决定)。
sk_receive_queue和sk_write_queue:接收缓冲队列和发送缓冲队列,队列里排列的是套接字缓冲区struct sk_buff,队列中的struct sk_buff的字节数总和不能超过缓冲区大小的设定。在sock实例创建的时候初始化的,最开始为空的队列(双向链表)。
struct inet_sock:这是INET域专用的一个socket表示,它是在struct sock的基础上进行的扩展,在基本socket的属性已具备的基础上,struct inet_sock提供了INET域专有的一些属性,比如TTL,组播列表,IP地址,端口等,完整定义如下:
struct inet_sock { struct sock sk; #if defined(CONFIG_IPV6) || defined(CONFIG_IPV6_MODULE) struct ipv6_pinfo *pinet6; #endif __u32 daddr; //IPv4的目的地址。 __u32 rcv_saddr; //IPv4的本地接收地址。 __u16 dport; //目的端口。 __u16 num; //本地端口(主机字节序)。 __u32 saddr; //发送地址。 __s16 uc_ttl; //单播的ttl。 __u16 cmsg_flags; struct ip_options *opt; __u16 sport; //源端口。 __u16 id; //单调递增的一个值,用于赋给iphdr的id域。 __u8 tos; //服务类型。 __u8 mc_ttl; //组播的ttl __u8 pmtudisc; __u8 recverr:1, is_icsk:1, freebind:1, hdrincl:1, //是否自己构建ip首部(用于raw协议) mc_loop:1; //组播是否发向回路。 int mc_index; //组播使用的本地设备接口的索引。 __u32 mc_addr; //组播源地址。 struct ip_mc_socklist *mc_list; //组播组列表。 struct { unsigned int flags; unsigned int fragsize; struct ip_options *opt; struct rtable *rt; int length; u32 addr; struct flowi fl; } cork; };
sock_create是创建socket的主要位置,其中sock_create又调用了__sock_create
int __sock_create(struct net *net, int family, ...)
{
struct socket *sock;
const struct net_proto_family *pf;
......
// 分配socket对象
sock = sock_alloc();
// 获得每个协议族的操作表
pf = rcu_dereference(net_families[family]
// 调用指定协议族的创建函数,对于AF_INET对应的就是inet_creat
err = pf->create(net, sock, protocol, kern);
}
在__sock_create里,首先调用sock_alloc来分配一个struct socket的内核对象,接着获取协议族的操作函数表并调用其create方法,对于AF_INET协议族来说,执行的是inet_create方法。
static int inet_create(struct net *net, struct socket *sock, int protocol, int kern)
{
struct sock *sk;
list_for_each_entry_rcu(answer, &inetsw[sock->type], list) {
// 将inet_stream_ops赋值到socket->ops上
sock->ops = answer->ops;
// 获得tcp_prot
answer_prot = answer->prot;
// 分配sock对象,并把tcp_prot赋值到sk->prot上
sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot);
// 对sock对象进行初始化
sock_init_data(sock, sk);
}
}
static struct inet_protosw inetsw_array[] =
{
{
.type = SOCK_STREAM;
.protocol = IPPROTO_TCP,
.prot = &tcp_prot,
.ops = &inet_stream_ops,
.no_check = 0,
.flags = INET_PROTOSW_PERMANENT | INET_PROTOSW_ICSK,
},
}
在inet_create中,根据类型SOCK_STREAM查找到对于TCP定义的操作方法实现集合inet_stream_ops和tcp_prot,并把它们发别设置到socket->ops和sk->prot上。
最后的sock_init_data将sk中的sk_data_ready函数指针进行了初始化(也包括设置其他函数指针),设置为默认的sock_def_readable,同时也会初始化sk_receive_queue和sk_write_queue为空队列
inetsw_array存储了AF_INET类型套接字的的所有网络协议
当软中断上收到数据包时会通过调用sk_data_ready函数指针(实际上被设置成了sock_def_readable)来唤醒sock上等待的进程。
至此一个tcp对象,确切的说是AF_INET协议族下的SOCK_STREAM对象就算创建完成了,这里花费了一次socket系统调用的开销。
三、内核和用户进程协作之阻塞方式
同步阻塞IO总体流程如下
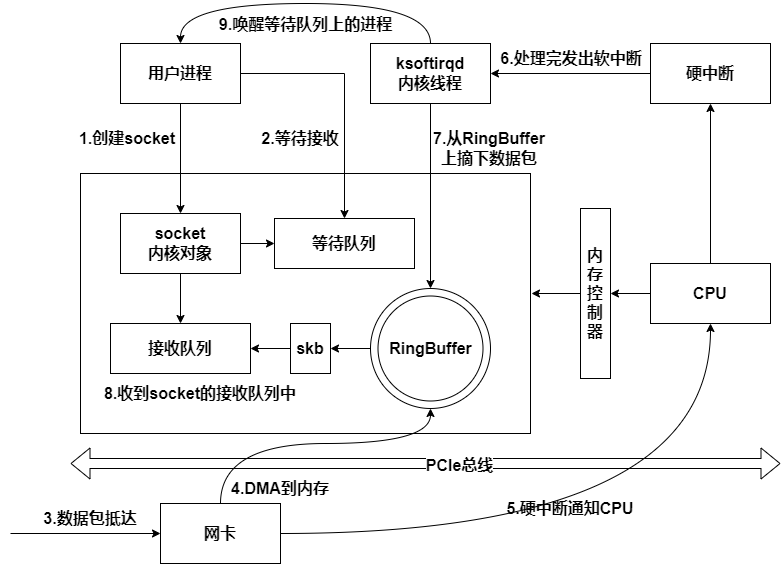
1)等待接收消息
查看recv函数的底层实现。首先通过strace命令追踪,可以看到clib库函数recv会执行recvfrom系统调用。
进入系统调用后,用户进程就进入了内核态,执行一系列的内核协议层函数,然后到socket对象的接收队列中查看是否有数据,没有的话就把自己添加到socket对应的等待队列里然后让出CPU,操作系统选择下一个就绪状态的进程来执行。
SYSCALL_DEFINE6(recvfrom, int, fd, void __user *, ubuf, size_t, size,
unsigned int, flags, struct sockaddr __user *, addr,
int __user *, addr_len)
{
struct socket *sock;
// 根据传入的fd找到socket对象
sock = sock_lookup_light(fd, &err, &fput_needed);
......
err = sock_recvmsg(sock, &msg, size, flags);
......
}
后续的调用顺序为:
sock_recvmsg => __sock_recvmsg => __sock_recvmsg_nosec
在__sock_recvmsg_nosec中会去调用socket对象proto_ops里的recvmsg,在AF_INET中其指向的是inet_recvmsg方法。
而在inet_recvmg中,会去调用socket中的sock对象的sk->sk_prot->recvmsg,在SOCK_STREAM中它的实现是tcp_recvmsg方法。
int tcp_recvmsg(struct kiocb *iocb, strcut sock * sock, struct msghdr *msg,
size_t len, int nonblock, int flags, int *addr_len)
{
int copied = 0;
......
// 如果设置了MSG_WAITALL,则target==len,即recv函数中的参数len
// 如果没设置MSG_WAITALL,则target==1
target = sock_rcvlowat(sk, flags & MSG_WAITALL, len);
do {
// 遍历接收队列接收数据
skb_queue_walk(&sk->sk_receive_queue, skb) {
......
}
......
}
if(copied >= target) {
release_sock(sk);
lock_sock(sk);
} else // 如果没有收到足够数据,启用sk_wait_data阻塞当前进程
sk_wait_data(sk, &timeo);
}
可以看到这里会去遍历socket的接收队列,如果接收到的数据不满足目标数量则会阻塞当前进程,具体阻塞方法的实现逻辑如下
int sk_wait_data(struct sock *sk, long *timeo)
{
// 当前进程(current)关联到所定义的等待队列项上
DEFINE_WAIT(wait);
// 调用sk_sleep获取sock对象下的wait并准备挂起,将进程状态设置为可打断
prepare_to_wait(sk_sleep(sk), &wait, TASK_INTERRUPTIBLE);
set_bit(SOCK_ASYNC_WAITDATA, &sk->sk_socket->flags);
// 通过调用schedule_timeout让出CPU,如何进行睡眠
rc = sk_wait_event(sk, timeo, !skb_queue_empty(&sk->sk_receive_queue);
......
}
#define DEFINE_WAIT(name) DEFINE_WAIT_FUNC(name, autoremove_wake_function)
#define DEFINE_WAIT_FUNC(name, function) wait_queue_t name = { \
.private = current \
.func = function \
.task_list = LIST_HEAD_INIT((name).task_list) }
首先在DEFINE_WAIT宏下**,定义了一个等待队列项wait**,在这个新的等待队列项上注册了回调函数autoremove_wake_function,并把当前进程描述符current关联到其.private成员上。
task_list = LIST_HEAD_INIT((name).task_list)将wait_queue_t的task_list成员初始化为一个空的链表头。LIST_HEAD_INIT是一个宏,它接受一个list_head类型的变量,并将它初始化为一个空的链表头。在这个宏定义中,(name).task_list实际上就是新定义的wait_queue_t变量的task_list成员。
所以,这行代码的意思就是将新定义的wait_queue_t变量的task_list成员初始化为一个空的链表头。这是必要的步骤,因为在wait_queue_t被添加到等待队列之前,它的task_list必须被初始化为一个有效的链表节点。prepare_to_wait()中会将wait变量的task_list成员添加到wait_queue_head_t类型的等待队列中。也就是说,task_list成员会被链接到sk_sleep()返回的等待队列中。
typedef struct __wait_queue_head wait_queue_head_t; struct __wait_queue_head { spinlock_t lock; struct list_head task_list; };
紧接着调用sk_sleep获取sock对象下的等待队列列表头wait_queue_head_t。
接着调用prepare_to_wait来把新定义的等待队列项wait插入sock对象的等待队列,这样后面当内核收完数据产生就绪事件的时候,就可以查找socket等待队列上的等待项,进而可以找到回调函数和等待该socket就绪时间的进程了。
最后调用sk_wait_event让出CPU,进程将进入睡眠状态,这会导致一次进程上下文的开销,而这个开销是昂贵的,大约需要花费几个微秒的CPU时间。
2)软中断模块
上篇文章中我们讲到了网络包到网卡之后是怎么被网卡接收最后再交给软中断处理的,最后讲到了ip_rcv根据inet_protos和数据包的协议将包交给上层协议栈的处理函数。软中断(也就是ksoftirqd线程)收到数据包以后,发现是TCP包就会执行tcp_v4_rcv函数,这里直接从TCP协议的接收函数tcp_v4_rcv开始。
int tcp_v4_rcv(struct sk_buff *skb)
{
......
th = tcp_hdr(skb); // 获取tcp header
iph = ip_hdr(skb); // 获取ip header
// 根据数据包header中的IP、端口信息查找对应的socket
sk = __inet_lookup_skb(&tcp_hashinfo, skb, th->source, th->dest);
......
// socket未被用户锁定
if(!sock_owned_by_user(sk)) {
{
if(!tcp_prequeue(sk, skb))
ret = tcp_v4_do_rcv(sk, skb);
}
} else
// 如果数据包被用户进程锁定,则数据包进入后备处理队列,并且该进程进入
// 套接字的后备处理等待队列sk->lock.wq
sk_add_backlog(sk, skb);
}
首先根据收到的网络包的header里的source和dest信息在本机上查询对应的socket。
tcp_hashinfo是一个散列表,用于存储所有活动的TCP套接字,从中查找与这个数据包对应的sock(即struct sock实例)。如果找到了匹配的套接字,就说明有一个连接正在接收这个数据包的源IP和端口发送的数据。
找到以后,首先要判断socket是否已经被用户锁定。
在Linux中,如果一个 sock 对象被用户进程锁定(例如,用户进程正在调用 recv 等系统调用读取数据),那么内核就不应该直接修改 sock 的状态,而应该将接收到的数据包放入后备处理队列,稍后再处理(当数据包被添加到后备处理队列后,这个数据包的处理就结束了,只有当 socket 变为空闲状态,那些在后备处理队列中的数据包才会被处理,通常这个处理过程就包括将数据包添加到接收队列中)。
如果socket没有被锁定,则调用tcp_prequeue尝试将数据包添加到sock的预处理队列中。如果添加成功则返回1,否则返回0。
在这个函数里面,会对 sysctl_tcp_low_latency 进行判断,也即是不是要低时延地处理网络包。如果把 sysctl_tcp_low_latency 设置为 0,那就要放在 prequeue 队列中暂存,这样不用等待网络包处理完毕,就可以离开软中断的处理过程,但是会造成比较长的时延(因为数据包的处理延迟到了进程被调度的时候。对于接收数据包而言没有区别,因为都是需要到进程被调度时才拷贝到用户空间。但是由于TCP协议处理被延迟,导致ACK的发送延迟,从而使数据发送端的数据发送延迟)。如果把 sysctl_tcp_low_latency 设置为 1,则调用 tcp_v4_do_rcv()立即处理。
实际上代码中较新的版本已经没有了tcp_prequeue()函数。之所以取消prequeue,是因为在大多使用事件驱动(epoll)的当下,已经很少有阻塞在recvfrom()或者read()的服务端代码了。
如果数据包没有加入预处理队列则进入接收的主体函数tcp_v4_do_rcv。
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{
if(sk->sk_state == TCP_ESTABLISHED) {
// 执行链接状态下的数据处理
if(tcp_rcv_established(sk, skb, tcp_hdr(skb), skb->len)) {
rsk = sk;
goto reset;
}
return 0;
}
// 其他非ESTABLISHED状态的数据包处理
......
}
int tcp_rcv_established(struct sock *sk, struct sk_buff *skb, const struct tcphdr *th, unsigned int len)
{
......
// 接收数据放到队列中
eaten = tcp_queue_rcv(sk, skb, tcp_header_len, &fragstolen);
// 数据准备好,唤醒socket上组色调的进程
sk->sk_data_ready(sk, 0);
}
假设处理的是ESTABLISHED状态下的包(即已经完成握手,建立连接),这样就又进入了tcp_rcv_established函数进行处理。
在tcp_rcv_established中完成了将接收到的数据放到socket的接收队列尾部,并调用sk_data_ready来唤醒在socket上等待的用户进程(创建socket时在sock_init_data函数里将该指针设置成了sock_def_readable)。
**唤醒进程时,即使等待队列里有多个进程阻塞着,也只唤醒一个进程,避免惊群。**会从头部开始依次检查每一个进程,看看是否满足唤醒的条件。如果满足条件,就将该进程唤醒。
在等待队列中,进程是按照它们进入队列的顺序排列的,即先进入队列的进程在队列的前面,后进入队列的进程在队列的后面
在前面调用recvfrom时,当数据不够后调用的sk_wait_data函数中使用DEFINE_WAIT定义了等待队列项的细节,并且把curr->func设置成了autoremove_wake_function,那么在唤醒进程时会去调用这个函数,它会去调用default_wake_function将因为等待而被阻塞的进程唤醒。这个函数执行完之后,这个进程就可以就可以被推入可运行队列里,在这里又将产生一次进程上下文切换的开销。
3)同步队列阻塞总结
同步阻塞方式接收网络包的整个过程分为两个部分:
- 我们自己的代码所在的进程:我们调用的socket()函数会进入内核态创建必要的内核对象。recv()函数会在进入内核态以后负责查看接收队列,以及在没有数据可以处理的时候把当前进程组色调,让出CPU。
- 硬中断、软中断上下文:在这些组件中,将包处理完后会放到socket的接收队列中,然后根据socket内核对象找到其等待队列中正在因为等待而被阻塞掉的进程,将它唤醒。
每次一个进程专门为了等待一个socket上的数据就被从CPU上拿出来,然后换上另一个进程。等到数据准备好,睡眠的进程又会被唤醒,总共产生两次进程上下文切换开销。根据业界的测试,每一次切换大约花费3-5微妙。
然而从开发者的角度而言,进程上下文切换其实没有做有意义的工作。如果是网络IO密集型的应用,CPU就会被迫不停地做进程切换这种无用功。
这种模式在客户端角色上现在还存在使用的情形,因为你的进程可能确实需要等MySQL的数据返回成功之后才能渲染页面返回给用户,否则什么也干不了。
而在服务端角色上,这种模式完全无法使用。因为这种模型里的socket和进程是一对一的,现在的单台机器要承载成千上万甚至更多的用户连接请求,如果用上面的方式,就得为每个用户请求都创建一个进程,否则无法同时处理多个用户的请求,然而这肯定是不现实的。
所以我们需要更高效的网络IO模型!可前往深入理解Linux内核网络——内核与用户进程协作之多路复用方案(epoll)继续学习多路IO复用解决方案~
参考资料:
《深入理解Linux网络》—— 张彦飞